Table of contents
Introduction Link to heading
On February 15th, 2024, OpenAI unveiled Sora – an impressive new deep learning model that can generate videos and images from text prompts. Sora can generate videos up to a minute long, at various resolutions and aspect ratios. While the model is not currently available for testing, cherry-picked results from OpenAI suggest it vastly improves on the previous state of the art.1 OpenAI claims – somewhat pompously – that Sora is a “world simulator.”2 What’s a world simulator, you ask? Good question! Here is OpenAI’s stated motivation for training Sora:
We’re teaching AI to understand and simulate the physical world in motion, with the goal of training models that help people solve problems that require real-world interaction.3
The technical report elaborates on OpenAI’s understanding of the theoretical significance of Sora:
Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.4
These bold statements are taken from blog posts – including the terse “technical report” – that can only be characterized as marketing documents rather than academic articles (let alone peer-reviewed research). It’s not the first time we’ve seen such language from companies working on video generation. Take for example this aspirational statement from Runway, one of the leading startups working on video generation:
A world model is an AI system that builds an internal representation of an environment, and uses it to simulate future events within that environment. […] You can think of video generative systems such as Gen-2 as very early and limited forms of general world models.5
Beyond PR posturing, these claims touch on genuinely interesting questions about the internal structure of state-of-the-art video generation models. Unfortunately, buzzwords like “world simulators” and “general world models” are not particularly helpful to formulate these questions clearly. What follows is an attempt at articulating what, exactly, it would mean for these neural networks to have an internal model of the physical world, and whether we have any evidence that systems like Sora do.
The progress of video generation Link to heading
Back in 2021, I wrote an article on how deep learning might change the traditional taxonomy of audiovisual media.6 In this article, I noted that generating videos was significantly harder than generating images, and made the following off-hand remark:
Nonetheless, it is plausible that we will be able to synthesize realistic and coherent video scenes at relatively high resolution in the short to medium term.
When I wrote this, the state of the art for video synthesis looked like that:

These short “videos” are from a model called MoCoGAN-HD.7 The authors framed the problem of video synthesis as discovering a trajectory in the latent space of a static image generation model, which allowed them to leverage existing research on disentangling representations in generative adversarial networks. This was undoubtedly a clever trick, which got the paper a spotlight at the 2021 ICLR conference. Yet the method and results already seem from a distance past.
Less than three years of continuous progress later, OpenAI’s Sora has just set a new bar for video generation. One might even argue that Sora’s (cherry-picked) outputs fit my description from 2021 of what might become possible in the short to medium term. Take a look for yourself:
Some things are particularly striking about outputs from Sora shared by OpenAI. First, they look incredibly realistic, at times virtually indistinguishable from real videos. If you focus on frozen frames, the high resolution, texture detail, and composition all contribute to this unprecedented degree of realism:






But the most impressive aspect of Sora is without a doubt its temporal consistency. Generating videos is much harder than generating still images, because videos must maintain continuity over time. This requires depicting an incredibly wide range of details consistently from one frame to the next. For example, it includes coherently matching or modifying the attributes of scene elements, such as objects and characters, over time – static attributes like shape and texture generally remain unchanged, while dynamic attributes like motion and interactions change according to the laws of physics and the narrative context. Objects may enter or leave the frame, occlude each other, collide, respond to various forces, get deformed; they should not randomly pop up or disappear, morph into arbitrary textures and shapes, or move in mechanically implausible ways. Camera motion also introduces additional challenges, as the 3D geometry and lighting of the scene and its elements must remain consistent under rotation, tilt, pan, zoom, etc. The same applies to scene transitions like spatial jump cuts, which may occur within a single generated sequence.
The following output is a good example of how well Sora can meet these challenges:
Notice how the geometry and main elements of the scene remain consistent despite the fast camera motion. Of course, it’s still far from perfect; eagled-eyed viewers will notice strange things happening in the background. The sequence is neither fully coherent nor fully realistic. But that’s an incredibly high bar to clear, and Sora does much better than its competition. We’ve certainly come a long way since MoCoGAN-HD in a few short years.
How Sora (probably) works Link to heading
How did we get there? The technical report is scant on details, but gives a number of clues about Sora’s architecture. NYU’s Saining Xie, whose own work laid the foundation for one of Sora’s key architectural features, helpfully distilled what we can infer from known information.8
At its core, Sora is a Diffusion Transformer (DiT), an architecture designed by Saining Xie and Bill Peebles (also one of the lead authors of Sora).9 A DiT is a diffusion model with a Transformer backbone. Familiar image generation models like Stable Diffusion are latent diffusion models. They use a pre-trained variational autoencoder (VAE) to compress raw images from pixel space to latent space; the diffusion model is then trained on the learned lower-dimensional latent space from the VAE, instead of the high-dimensional pixel space. This diffusion process is generally implemented with a U-Net backbone. U-Net is a convolutional neural network originally developed for image segmentation, and later adapted for denoising diffusion.
The DiT architecture takes inspiration from latent diffusion models, but replaces the U-Net backbone with a modified Vision Transformer (ViT). ViTs are Transformer models (like language models) that are specifically adapted for visual tasks; instead of taking linguistic tokens as input, they receive sequences of image patches. For example, an image can be split in 16x16 patches, resulting in 256 input tokens for the Transformer. Similarly, the modified ViT at the core of DiTs takes latent representations of image patches from the VAE as sequential input tokens. DiTs have a few benefits over vanilla latent diffusion models with U-Net: they are more efficient, scale better, and are easily adaptable to variable resolutions for generation.
The DiT architecture had already been adapted for text-conditioned image and video generation before Sora.10 OpenAI’s own solution uses what they call a “video compressor network”, which is probably a VAE adapted to video. The basic idea is the same as with the original DiT:
- The video compressor network compresses raw video inputs into latent spatiotemporal representations
- Compressed videos are turned into “spacetime patches” fed to the Diffusion Transformer as input tokens
- After the last Transformer block, a decoder model (trained jointly with the video compressor network) maps generated latent representations back to pixel space
That’s the gist of it, as far as I can tell. As with previous achievements from OpenAI – GPT-3 comes to mind –, the consensus seems to be that there is nothing genuinely groundbreaking about Sora’s architecture. As Saining Xie puts it, it’s essentially a DiT adapted for video without additional bells and whistles. As such, Sora is largely an engineering feat, and yet another testament to the power of scaling. The technical report provides a vivid illustration of improvements of sample quality as training compute increases. As with language models, it seems that certain capabilities emerge with scale; naturally, Sora has reignited heated debates about how far one can get with sheer scaling.
Sora does benefit from a few other clever tricks. One of them is the re-captioning technique pioneered with DALL-E 3. OpenAI trained a highly descriptive captioner model, and used it to caption all videos in Sora’s training set. This increases the adherence of generated videos to complex text prompts. All user prompts for the trained Sora model are also augmented by a GPT model that adds additional detail (this is also similar to how ChatGPT augments prompts for DALL-E 3).
One of the big unknowns with Sora, as with other OpenAI models, is the training data. We know that high-quality training data is key to the performance of generative models, and might matter just as much as model size and training compute past a certain scale. High-quality data augmentation is all the rage; and indeed, there is speculation that OpenAI trained Sora partially on synthetic data – specifically outputs from a video game engine like Unreal Engine 5. This would make sense to force the model to learn how to depict the same scene in different configurations (different angles, scene composition, camera motion paths, etc.). This might partly explain why Sora’s outputs are so consistent.
One last thing to note before we move on to more philosophical territory: as with standard latent diffusion models, it’s important to remember that the diffusion process between the video compressor network encoder and the decoder happens entirely in latent space, not in pixel space. We’ll come back to that point later.
The simulation hypothesis Link to heading
Everyone can agree that Sora is an impressive model, at least if it holds up to expectations set up by cherry-picked outputs. But is there more to it than making pretty videos? OpenAI’s team certainly seems to think so. The technical report claims that Sora acquires “emerging simulation capabilities” with scale. It mentions scene consistency through dynamic camera motion, occlusion, object permanence, and video game simulation as examples of such capabilities. It goes on to conclude:
These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them.
Let’s call this the simulation hypothesis.11 The problem with this hypothesis, as stated, is that it’s extremely vague. What would it actually mean for a video generation model to simulate the physical world? And what kind of evidence could support that claim? Let’s take these questions one by one.
In the wake of Sora’s release, prominent figures in the AI industry have stated their own understanding of the simulation hypothesis. Jim Fan from NVIDIA described Sora as “a data-driven physics engine.” He clarified what this was intended to mean as follows:
Sora learns a physics engine implicitly in the neural parameters by gradient descent through massive amounts of videos. Sora is a learnable simulator, or “world model”.12
Sora must learn some implicit forms of text-to-3D, 3D transformations, ray-traced rendering, and physical rules in order to model the video pixels as accurately as possible. It has to learn concepts of a game engine to satisfy the objective.13
The physics engine terminology is somewhat confusing, especially given the suspicion that Sora was trained on scenes from Unreal Engine 5, so let’s clear this up first. As far as I know, nobody (including Jim Fan) is seriously suggesting that Sora literally has a physics engine in the loop at inference time. In other words, it doesn’t make function calls to Unreal Engine to generate videos. Not only because it’s entirely unclear how this would even work (where would the assets, rigging, animation come from?), but also because Sora is a DiT, and that’s not how DiTs work at all (see the previous section).
Note that having a neural network make calls to a physics engine is something that has actually been attempted before, not for video generation, but for physical reasoning. A 2023 Google Brain paper by Ruibo Liu and colleagues augmented a language model to improve its performance on physical reasoning question by simulating possible outcomes with a physics engine (DeepMind’s MuJoCo), using the results of these simulations these as hints in the prompt:14
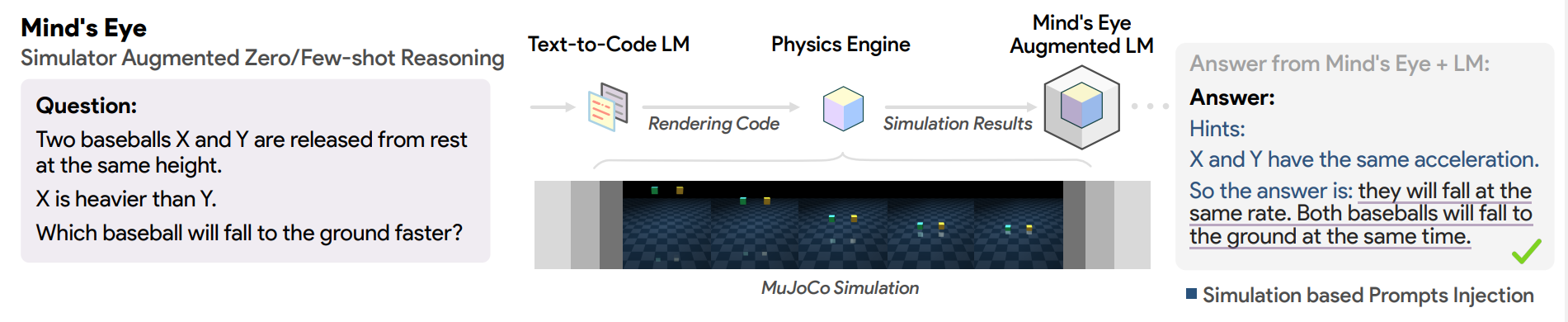
This line of work has also been explored by Josh Tenenbaum’s lab at MIT, using a language model to translate natural language queries into code expressions in a probabilistic programming language.15 To enable reasoning about physical situations described in language, Lionel Wong and colleagues integrated a physics simulation engine into this framework. They added a simulate_physics function to the probabilistic generative program, which takes an initial symbolic scene state specifying object properties like positions and velocities, and returns scene states with these properties updated over time according to physics, modeling movements and collisions. By adding physics simulation as a function call, language descriptions can be translated to query and reason about how described physical situations would play out over time. This is decidedly not anywhere close to what Sora does. Sora is an end-to-end neural network, not a neurosymbolic system.
How, then, should we understand the claim that Sora is akin to a “data-driven physics engine” that simulates the physical world? Nando de Freitas from Google DeepMind puts it at follows:
The only way a finite sized neural net can predict what will happen in any situation is by learning internal models that facilitate such predictions, including intuitive laws of physics.16
We’re getting closer to a clear statement of the simulation hypothesis: a good-enough video generation model based on an end-to-end neural network architecture with a finite set of parameters should be expected to acquire internal models of the physical world during training, because this is the most effective way – perhaps the only way – for such a neural network to generate coherent and realistic videos of arbitrary scenes.
Does Sora literally induce the laws of physics from 2D videos? As stated, this may seem absurd. For example, it seems wildly implausible that Sora would somehow acquire an internal model of the laws of thermodynamics. But game engines don’t typically model these laws either. While they might simulate heat effects (fire, explosions) and work (objects moving against friction), these simulations are usually highly abstracted and do not adhere strictly to thermodynamic equations. They simply don’t need to, because their focus is on the visual and interactive believability of the rendered scene rather than strict physical accuracy. Could Sora be doing something similar? If we want to begin answering this question, we need to talk about intuitive physics.
Intuitive physics Link to heading
Let’s take a brief detour through another system that clearly demonstrates a fairly sophisticated understanding of physics. I’m talking, of course, about people. Not just trained physicists – laypeople, including children. We all have an intuitive understanding of the physical world. This is what cognitive scientists appropriately call intuitive physics: the type of quick, automatic everyday reasoning that allows people to know what will happen when various objects interact, without needing to consciously think through the physics calculations. Suppose you see a ball rolling along the floor towards a wall; you will immediately have the intuitive sense that the ball will bump into the wall and bounce back rather than passing through it. You simply know this is going to happen, without needing to consciously perform a bunch of calculations.
Even young infants seem to know intuitive physics. This has been studied in experiments that test infant’s expectations about various physical properties. These experiments involve familiarizing infants to certain physical events with objects, such as an object being placed behind a screen. After familiarization, the events are changed during test trials to produce various violations of basic physics principles regarding object behavior. If infants look longer at these new impossible events compared to further familiar test trials, the increase in looking time is taken to indicate detection of a violation of the infant’s expectations about intuitive physics (this is known as the “violation-of-expectation” paradigm).17
Violation-of-expectation studies suggest that young infants already have stable expectations about various aspects of the physical world, including object permanence (objects continue to exist even when out of sight), solidity (objects don’t pass through each other), and cohesion (objects are connected wholes that move together). Even at a very young age, infants seem to expect objects will obey certain physical rules, and generalize these expectations to new objects rather than having to individually learn affordances for each specific object. This early knowledge is often taken as evidence that we have strong innate constraints on object representations – part of a “core knowledge” we are born with, rather than something we learn during development. This conclusion is debated, but we don’t need to get into that here.18 The important point is that humans are surprisingly good at making sense of the physical world and its rules from a very young age, whether that’s innate, rapidly learned, or a bit of both.
How do we do this? This is where things get a bit complicated – and more controversial. One prominent hypothesis in cognitive science is that people mentally simulate physical events using an “intuitive physics engine” (IPE) that approximates realistic physical dynamics, similarly to the physics engines used in computer games.19 On this view, when we observe a physical scenario, we construct a mental representation of the objects, properties, and forces at play based on noisy perceptual evidence, then run an internal simulation to predict what will happen next.
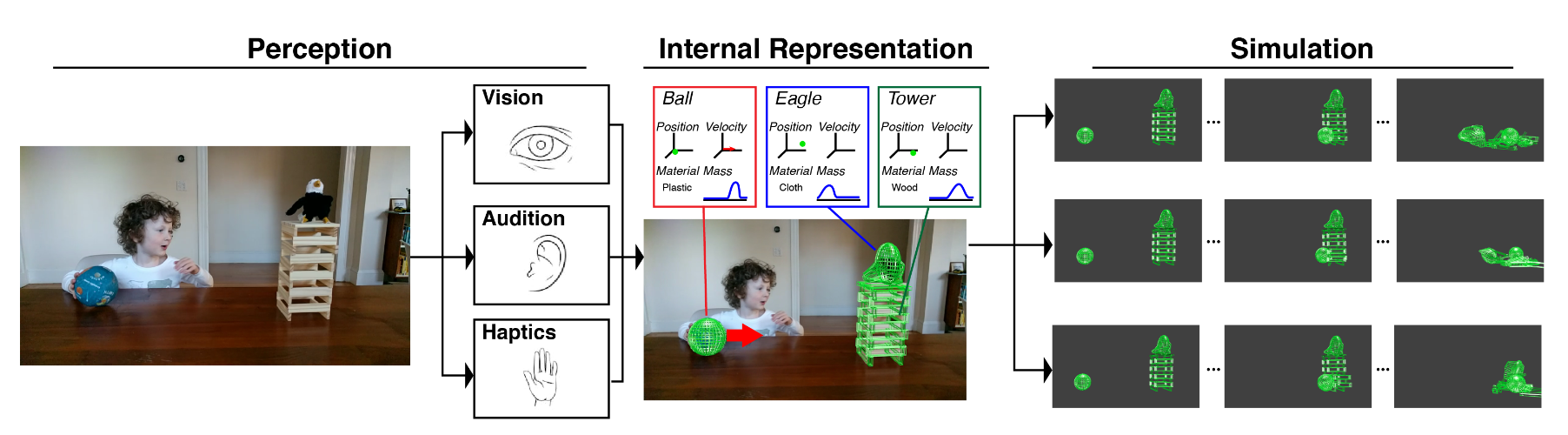
More precisely, the IPE serves as a generative causal model mapping from unobservable physical variables and uncertainty to observable physical phenomena through stochastic simulation based on imprecise but broadly accurate physical principles. Let’s briefly unpack this. The IPE represents latent physical variables (like mass, friction, elasticity, etc.) for objects in a physical scenario. These variables are not directly observable, but govern how objects behave in the scenario. Uncertainty is required to handle perceptual noise and capture humans’ graded confidence in physical reasoning. It comes from two main sources: perceptual uncertainty about the exact observable state of the world (e.g. objects’ precise positions and velocities), and stochasticity in how the physical dynamics unfold over time, especially for complex events like collisions.
The IPE simulates how latent variables and uncertainty propagate over time using physical principles that are locally consistent but approximate – for example, it does not strictly enforce conservation of energy. By running many simulations, the IPE outputs probability distributions over plausible future states of the world. In principle, it can thus support not only prediction about how a scene will unfold over time, but also inference about unobserved physical properties of objects, causal reasoning using counterfactual simulation of alternative outcomes, and even planning by evaluating expected outcomes of possible actions to maximize utility.
The analogy between the IPE and physics engines used in video games and computer graphics meant to be taken quite seriously. There is, admittedly, a key difference: the inputs and outputs of physics engines are fixed values, not probability distributions. But physics engines do provide a useful proof of concept for computationally tractable simulation of physical phenomena through approximation. As mentioned above, they are not designed for high-fidelity simulations like aerospace engineering, but rather to produce subjectively plausible approximations tuned for human perception. Researchers like Tomer Ullman suggest that their efficiency constraints might mirror limited computational resources available for core cognition in humans and animals.20 Yet despite mathematical and algorithmic simplifications, they capture a rich subset of everyday phenomena on human scales. Similarly, the IPE must balance realism, interactivity and tractability.
There is an increasingly large body of work putting this hypothesis to the test. Probabilistic models based on the IPE can closely fit human judgments about object stability, trajectories, collisions, containment, support, and fluid dynamics in a wide variety of tasks. These models also capture the development of intuitive physics in infancy. That said, there are also ongoing debates about the scope, limits, and even viability of the IPE hypothesis.
Critics point to cases where human physical reasoning deviates from the predictions of IPE-style simulations. These include systematic biases and errors as well as reliance on visual shortcuts. Some argue that alternative processes might better explain human intuitions about physics, including non-Newtonian mental models, and indeed deep learning models. Some argue that running physics engine-like programs may be incompatible with known limits on working memory, attention, and other bottlenecks for representing multiple objects and relationships at the same time and keeping track of them over time. Relatedly, the approximation strategies posited by proponents of the IPE may either deviate radically from simulation ideals or introduce new capacities that themselves require explanation. Finally, there are also deeper methodological concerns, with critics alleging that we have little evidence for literal IPEs at all, as opposed to more piecemeal mechanisms that achieve flexible, broad physical understanding without centralized simulation. On this view, supposed evidence for IPE often reflects post-hoc fitting rather than support for the core commitments of simulation theories.
These controversies are still raging, and this is not the place to take a deep dive into the relevant scientific literature.21 Let me focus on just one objection to the IPE hypothesis, which is particularly relevant to debates about video generation models. Some researchers argue that people’s judgments about physical scenarios sometimes depend only on superficial visual features rather than underlying physics. For example, deep neural networks such as ResNet-50 trained purely on static images can judge the stability of block towers with comparable performance to that of adult humans.22 People have also been found to rely on the appearance of block towers rather than physical constraints like friction, with toddlers ignoring shape entirely. On the face of it, evidence of reliance on the surface statistics of perceptual inputs seems to decrease the explanatory purchase of IPE-style simulations.
The common response from proponents of the IPE hypothesis is that evidence of reliance on heuristics can simply be interpreted as constraining the boundary conditions and mechanisms of IPE simulation. No model would claim unbounded use of physics simulations to handle all abstract reasoning – approximations are inevitable and built into the theory. But researchers remain divided over whether non-simulation processes operate alongside or supersede simulation in restricted contexts that elicit poor intuitions. Disentangling potentially complex interactions between perceptual mechanisms, qualitative heuristics and simulation remains a challenge to adequately explain the patchwork of human successes and failures observed across various physical reasoning tasks.
Where does that leave us? Here is the bottom line: when it comes to humans, at least, it is tempting to explain intuitive physical reasoning by postulating the existence of an IPE that performs probabilistic mental simulations about physical scenarios using approximate principles. This hypothesis is still debated, and there is arguably evidence for and against it. But there is at least a relatively plausible and well-thought-out case to be made for the simulation hypothesis, with a rich experimental literature to back it up. With that background in place, we can now come back to artificial neural networks.
World models Link to heading
Our detour through the literature on intuitive physics in psychology brings one important point to the fore: there is a prima facie difference between running mental simulations of physical scenarios and merely representing aspects of the physical world, such as object geometry. This distinction matters greatly when it comes to discussing the capacities of neural networks like video generation models. Unfortunately, it often gets lost in discussions of the nebulous concept of “world models.”
The phrase “world model” is one of those technical terms whose meaning has been so diluted as to become rather elusive in practice. In machine learning research, it mostly originates in the literature on model-based reinforcement learning, particularly from Juergen Schmidhuber’s lab in the 1990s. In this context, a world model refers to an agent’s internal representation of the external environment it interacts with. Specifically, given a state of the environment and an agent action, a world model can predict a future state of the environment if the agent were to take that action.
The aptly titled “World Models” paper by Ha and Schmidhuber (2018) expands on this idea in interesting ways.23 The world model incorporates a sensory component that processes raw observations and compresses them into a compact encoding. For example, this can be a VAE that encodes 2D image frame observations into a lower-dimensional latent space representation. A predictive model in the form of a recurrent neural network (RNN) is then used to capture temporal patterns by learning to predict future latent representations based on the history of actions, encoded observations, and reward signals experienced. Specifically, the RNN-based world model is trained to internally simulate and predict future latent observation encodings, rewards, and termination signals (done states) conditioned on previous experience.

Once this world model is sufficiently trained, it can emulate key components needed for the agent’s decision-making – generating simulated experiences containing observations, rewards, and done signals. Controllers can thus be trained entirely inside the “dream” experiences simulated by the world model, without needing the real environment. The benefit is that computationally expensive environments like those rendered by game engines can be substituted entirely with world model instantiations in the simulated latent space for efficient learning. Once trained inside its simulated dreams, the learned policy can then be tested in the real environment to assess how well the world model generalizes. If needed, iterative training can improve the world model over time using additional real experience collected.
This notion of “world model” is explicitly related to simulation. At a high level, the objective of a learned world model is essentially to simulate the key aspects of the environment from the agent’s perspective, based on its accumulated experience. Once trained, the VAE and the RNN can simulate fake experiences for the agent: the VAE decoder can reconstruct observations from sampled latent variables, while the RNN generates the dynamics of these latent states as well as rewards and done signals. So in effect, the world model can instantiate a simulated version of the environment using just learned parameters.
However, these “simulations” don’t involve anything like an IPE-style physics engine. The world model is trained end-to-end instead of making calls to a simulator with built-in physical principles. This is why Ha & Schmidhuber routinely describe the world modeling process in terms of “dreaming” or “hallucinating” rather than “simulating” (although they use that term too). The fake experiences conjured up by the world model do have a dream-like quality to them, because they are significantly less constrained than the simulations of a rigid physics engine. The report of the Embodied AI Workshop at the 2023 CVPR conference, coauthored by proponents of the IPE hypothesis like Josh Tenenbaum, states that simulations in the IPE “can be thought of as world modeling with strong inductive biases” right after describing Ha & Schmidhuber’s approach.24 This is an interesting description in this context; it suggests that the conceptual gap between IPE-style simulation and RL-style hallucination may not be as absolute as it may seem, but has to do with the strength of inductive biases and rigidity of simulation parameters, since one is supposed to be largely innate while the other is learned end-to-end.
Ha & Schmidhuber’s world model paper has influenced many subsequent works. Most recently, Google DeepMind presented Genie, a “foundation world model” that bridges the gap RL-style world models and video generation.25 While Genie is not a reinforcement learning system, at a high-level it presents key similarities with Ha & Schmidhuber’s framework. Instead of training a model-based RL agent on simulated environments, Genie generates an interactive environment where human users can control an agent through actions that impact future video generation. While “World Models” used the dynamics model for planning or policy optimization, Genie creates an action-conditional video prediction model that users can “play” by providing input actions to influence generated frames. In particular, Genie introduces the idea of unsupervised action space learning to avoid reliance on action labels during training. An action inference model extracts discrete latent actions from unlabeled videos by using future frame prediction as self-supervision. As a result, arbitrary videos can serve as training data instead of action-labeled examples. This is highly relevant to model-based RL, because agent policies could be trained inside of Genie’s simulations in principle.

Genie’s playable simulations have notable characteristics. For example, the model trained on videos of platformer games can emulate parallax in generated outputs, where foreground elements move faster than background elements when an action is taken. It also appears to emulate gravity and bounding boxes to handle collisions, as seen when a latent action involves the character jumping then falling onto a foreground element like a platform. While the physics of platformer games is primitive, Genie does appear to approximate key aspects of a 2D platformer game engine.
Another notion of “world model” worth mentioning that of Yann LeCun, which is prominently featured in his preferred joint embedding predictive architecture (JEPA).26 In LeCun’s framework, a world model is an internal predictive model of how the world works that an intelligent agent uses for planning and reasoning. It is taken to be a specific module within the agent’s cognitive architecture that serves two key functions:
- It estimates missing information about the current state of the world that was not provided by the agent’s perceptual system;
- It predicts multiple plausible future states of the world that could result from imagined sequences of actions proposed by the agent’s distinct “actor” module.
Crucially, the world model produces these estimations and predictions by manipulating abstract representations of relevant aspects of the world state, rather than raw perceptual signals. The abstraction allows the model to eliminate unpredictable details as well as enable multiscale planning. The predictions of the world model, parameterized by latent variables, are provided to the agent’s “cost” module which evaluates the expected outcome of taking those actions. This allows the agent to reason about and plan complex tasks by imagining action scenarios and their potential effects before taking them in the real world.
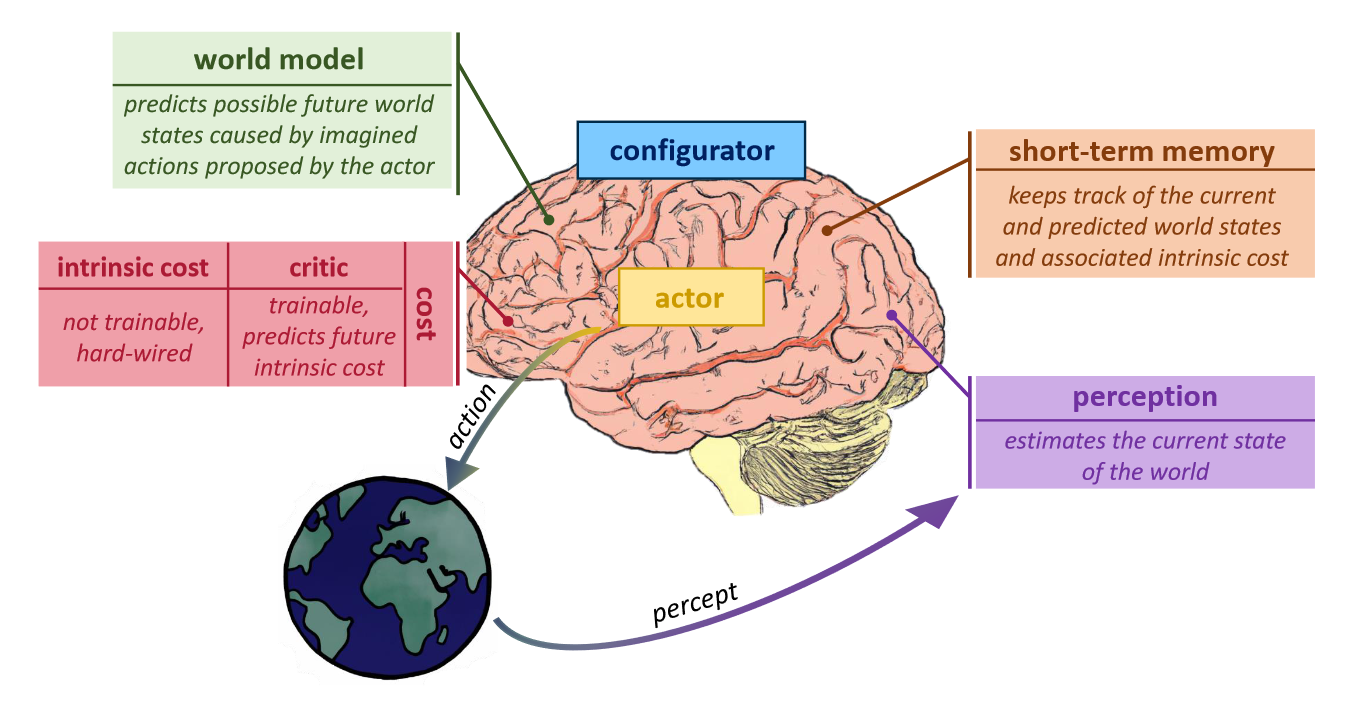
In the JEPA architecture, the world model module is implemented by the predictor network. The predictor network takes as input the abstract representations of the current world state produced by the context encoder network. These abstract representations encode the relevant aspects of the current world state for the task at hand. The predictor network also takes as input a proposed sequence of actions from the actor module. Its key purpose is to predict the sequence of abstract future world state representations that are likely to result from that sequence of actions. Crucially, because the predictions are made in the abstract representation space learned by the JEPA, the predictor network does not need to predict every detail of the future world state (unlike generative models that predict pixels). Unpredictable details can be discarded by the abstraction process. The predicted sequence of future world states can be evaluated by the cost module to estimate the expected outcome of taking the proposed action sequence. Accordingly, the actor module can iterate and search for an optimal sequence of actions that minimizes future cost.
This notion of world model bears some loose similarities with that used in model-based RL, although the JEPA architecture relies on a self-supervised learning objective. Interestingly, it was recently applied to video with V-JEPA, a self-supervised model that learns by predicting representations of masked spatio-temporal regions of videos in latent space. While V-JEPA does not have a “world model” in the richer sense of the architecture sketched above, it is meant as a stepping stone in that direction. One the key differences between V-JEPA and Sora is their respective learning objectives, and the downstream influence these presumably have on their latent representations. While Sora is trained for frame reconstruction in pixel space, V-JEPA is trained for feature prediction in latent space. According to LeCun, this should be expected to translate into drastic differences between their latent representations, and, specifically, whether these are useful for world modelling. On his view, a pixel-level generative objective is simply not that great to induce the kind of abstract representations that may be useful to plan and act in the world.
In other domains of deep learning research and cognitive science, the notion of world model is less tightly coupled with that of agent-centric simulation or prediction. Consider, for example, the definition given by Yildirim & Paul in a forthcoming paper:
World model: Structure-preserving, behaviorally efficacious representations of the entities, relations and processes in real-world. These representations capture, at an abstract level, their counterpart real-world processes (which are typically causal relations), in algorithmically efficient forms, so as to support relevant behaviors.27
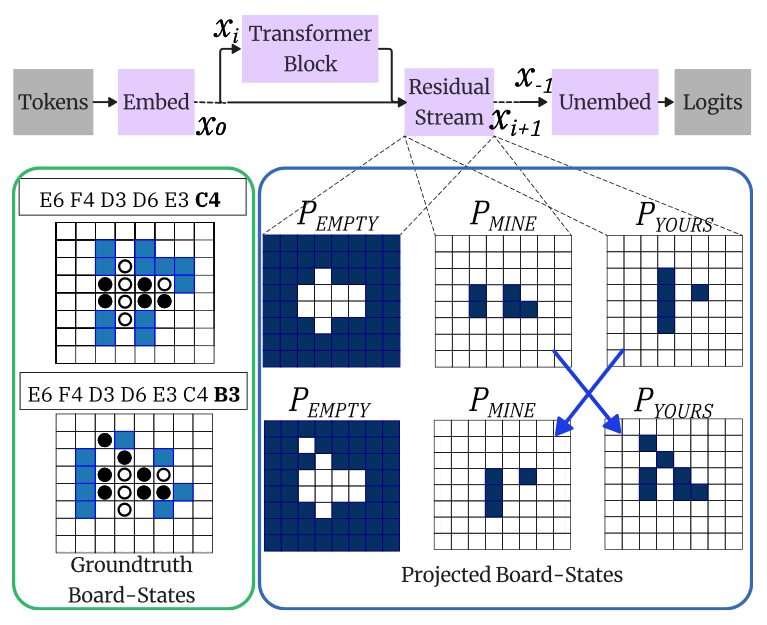
This definition is meant to apply in principle to systems such as Transformer-based large language models (LLMs); and indeed, the literature on LLMs is rife with discussions of whether such systems can acquire world models in the above sense.28 An interesting case study in that of Othello-GPT, an autoregressive Transformer model trained on sequences of moves from the boardgame Othello instead of linguistic tokens.29 Othello-GPT has no built-in knowledge of game rules or board structure, and learns only by predicting moves from game transcripts. After training, it can suggest legal moves with high accuracy when prompted with unseen move sequences. This raises the question whether the model actually represents properties of the game world, such as the state of the board, instead of relying on memorization and shallow heuristics.
What does it mean for a neural network to represent a property? Philosophical theories of representation suggest several key criteria:30
- The network must contain a pattern of activation that encodes correlational information about the target property;
- The network must actually make use of the encoded information to generate outputs;
- The pattern of activation that encodes correlational information about the target property may misrepresent that property for particular inputs in ways that degrade model performance.
The first criterion can be verified by probing the network using classifiers; if the target property can be reliably predicted from some pattern of activation in the network with simple (typically linear) probes, we can conclude that information about the property is available to the network. However, we also need to show that such information actually plays a causal role in the network’s behavior. This can only be shown by intervening on the network to see how behavior would change if the relevant pattern of activation was modified. This kind of counterfactual intervention is at the core of most interpretability techniques used in deep learning.
As it happens, interpretability research on Othello-GPT found that linear probes could decode information about the state of the board from the model’s interval activations.31 Specifically, Othello-GPT encodes the status of each tile on the board relative to the current player – as occupied by current player, occupied by opponent, or empty. Probes classifying the tiles according to these categories achieve near-perfect accuracy. What’s more, using these probes to perform interventions such as flipping the color of tiles (i.e., switching the occupying player’s identity) and erasing previously played tiles causally influences the model’s predictions about the next move as expected. This provides fairly strong evidence for the emergence of a “world model” in Othello-GPT, in the sense that the network encodes causally efficacious information about the board state (or “game world”) that enables it to keep track of player positions in order to predict legal moves.
Let me briefly mention one final notion of world model from the causal inference literature. This notion is essentially equivalent to that of causal model (sometimes also called “causal world model”). Judea Pearl, for example, seems to use the phrase “world model” in such a way. There are well-known reasons to doubt that any system that learns purely from observations could acquire a “world model” in that sense, except in toy domains (like Othello), because real-world observational data contain confounding variables. In their current incarnation, neither generative modeling nor deep reinforcement learning seem to fundamentally solve this problem, although this is the locus of a long-standing debate. That said, there is work suggesting that systems like GPT-4 can generate plausible counterfactuals, even if they don’t actually perform bona fide causal inference.32 This suggests that generative models trained purely from observational data can, in principle, approximate the behavior of a genuine causal agent if the training data is large and diverse enough.
Taking stock: people use the phrase “world model” in slightly different ways. World models in RL have to do with agent-centric predictions, and indeed simulation of future states of the agent’s environments (conditioned on the agent’s actions). World models in LeCun’s vision for autonomous machine intelligence also has to do with agent-centric predictions, albeit predictions in latent space learned through self-supervision. Neither generative models, nor RL models, nor even JEPA models meet the high bar set by the strong causal notion of “world model” from the causal inference literature. Finally, “world model” is also used more broadly to refer to structure-preserving representations of properties in a target input domain that go beyond surface heuristics. In this last sense, it can be applied to toy autoregressive models trained on game like Othello-GPT, and perhaps, more speculatively, to language models. What about video generation models like Sora? We can to look to image generation models for clues.
Scene representation in image generation Link to heading
As discussed, Sora is a Diffusion Transformer at its core. The DiT architecture is heavily inspired by latent diffusion models routinely used for image generation, although it swaps out the U-Net backbone with a Vision Transformer. A natural question to ask, then, is what kind of information image generation models based on latent diffusion actually encode. Specifically, do merely encode information about the surface heuristics of images? Or do they, similarly to Othello-GPT, encode information about the latent variables of visual scenes, such as their 3D geometry?
Unfortunately, few papers investigate this question. But those that do paint an intriguing picture. Zhan et al. (2023) proposed a method to assess whether latent diffusion models encode different physical properties of the 3D scene depicted in an image, with the following steps:
- Select a target physical property like scene geometry, lighting, viewpoint relations, etc.;
- Collect an image dataset with ground truth annotations for the target property;
- Extract features from different layers and time steps of a latent diffusion model by adding noise to input images from the collected dataset in the model’s latent space;
- Train a linear probe based on the diffusion model’s extracted features to answer questions related to the target physical property (e.g., “Are two regions on the same plane?”, “Is one region the shadow of the other?”);
- Evaluate the probe’s performance at predicting the target physical property based on the model’s features. High classification performance suggests that the model encodes information about the target physical property.
Using this method on a number of physical properties, the results suggest that models like Stable Diffusion encore information about 3D scene geometry (e.g., whether two image regions are on the same plane, or on perpendicular planes in 3D space), support relations (whether one object is being supported by another object underneath it against gravity), lighting (which image regions correspond to objects’ shadows) and relative depth (which of two image regions is closer or further from the camera viewpoint along the depth axis). Classification performance for occlusion (whether disconnected image regions actually belong to the same physical object) was lower.
Note that this paper merely showed that information about physical properties was decodable from the model’s activations, not that it was causally efficacious on model behavior – one the key criteria for the philosophical notion of representation. But another paper by Chen et al. (2023) addresses that gap. They started by creating a dataset of images generated by a latent diffusion model (Stable Diffusion), along with ground truth labels for salient (foreground) object segmentation and continuous depth values estimated by state-of-the-art models. They subsequently trained linear probes on the internal activations of the latent diffusion model at each sampling step to predict the salient object masks and depth values. Again, high prediction accuracy suggests that the model’s activations encode information about salient object segmentation and depth. To test if the encoded information plays a causal role on model behavior, they performed intervention experiments where they modified the model’s internal activations while keeping the text prompt and noise input unchanged. If information about the foreground object and depth are causally involved, the geometry of generated images should change accordingly.
For foreground objects, they intervened on the model’s activations in early denoising steps to match a modified object mask shifted to a new region of the image. Generating a new image after the intervention resulted in the foreground object being located in the new position in the output, suggesting the modified encoding causally impacts object placement. For depth, they translated the depth map sideways and updated the model’s encoded depth representation to match. Similarly, generating new image using this modified depth encoding resulted in congruent changes to the apparent depth of the output image.
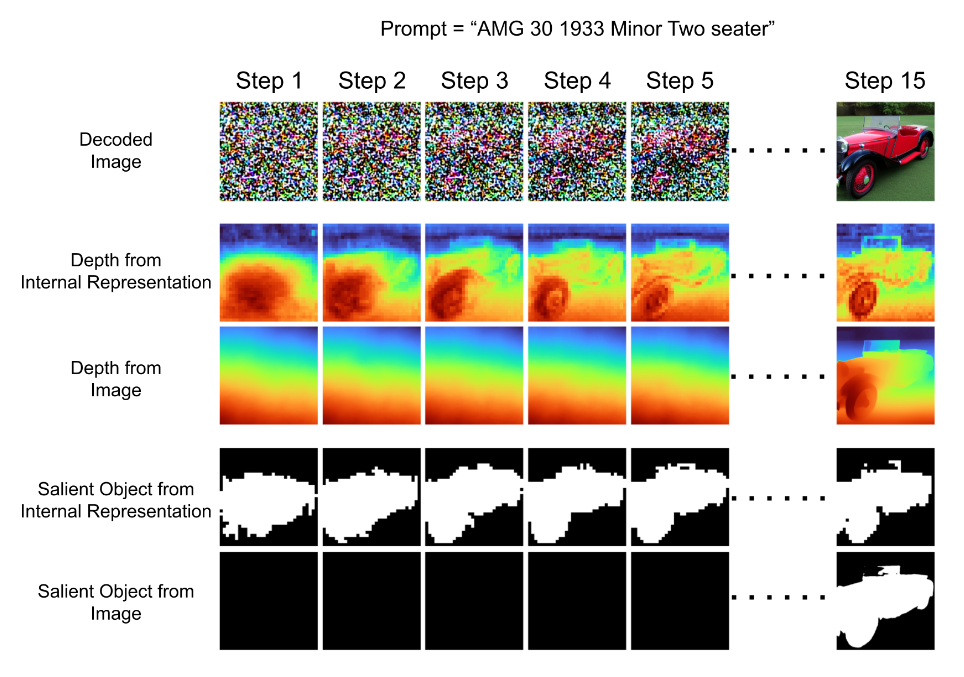
This experiment suggests that latent diffusion models like Stable Diffusion learn a linear representation of simple scene geometry, specifically related to the depth and foreground/background distinctions, even though they are trained solely on 2D images without explicit depth supervision. In addition, these representations emerge surprisingly early in the iterative sampling process, at stages where the image itself would still look like random noise to a human viewer and contain virtually no depth information (see the figure above). This suggests that latent diffusion models do much more than fitting to the surface statistics of pixel space. They induce latent information about depth and saliency because such information is useful for the objective of generating realistic looking images. This is strongly reminiscent of how Othello-GPT induces latent information about the board state because such information is useful for the objective of predicting game moves.
There is other relevant work on image generation models. For example, Low-Rank Adaptation (LoRA) can be used to extract intrinsic “scene maps”, such as surface normals and depth, directly from a latent diffusion model. This method can transform any image generation model into an intrinsic scene property predictor without requiring an additional decode network. Results suggest that fine-grained predictions about 3D scene geometry can be extracted by harnessing information already present within model parameters.
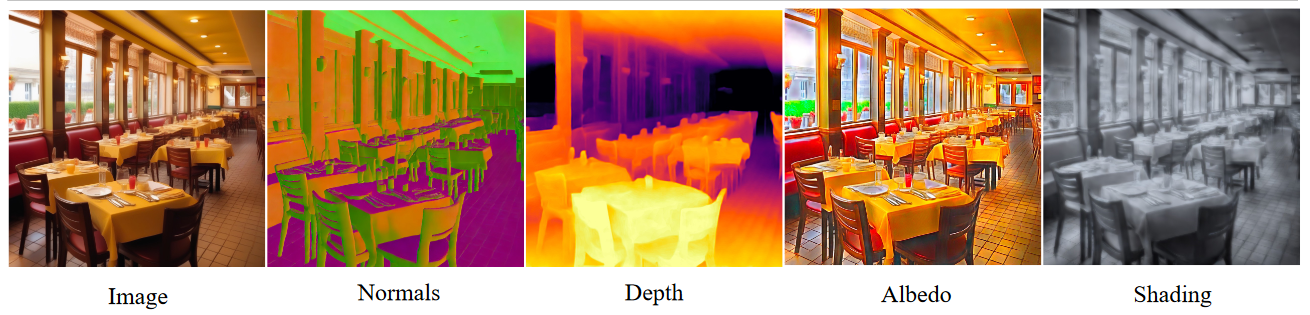
None of this entails that latent diffusion models represent various aspects of visual scenes’ 3D geometry perfectly. In fact, a trained eye can often notice various flaws in outputs. Physical inconsistencies can even be quantified, as Sarker et al. (2023) did, using classifiers. These include misalignment of objects and their shadows, as well as violations of projective geometry such as lines that fail to converge properly to vanishing points or that do not follow linear perspective:

It’s interesting to speculate about what it might take to fix these lingering flaws in generated images. One hypothesis is that the model tested (Stable Diffusion) is not large enough or trained on enough data. Scaling up parameter and dataset size might be sufficient to allow latent diffusion models to learn correct projective geometry, just as it was sufficient to fix many other issues with realism and coherence in previous generations of models. But there may also be more fundamental issues that prevent latent diffusion models from properly learning projective geometry. For example, their architecture may lack appropriate inductive biases. In that case, it is also possible that DiTs, benefiting from the Vision Transformer backbone, could alleviate the shortcomings of vanilla latent diffusion.
Be that as it may, probing and intervention studies with latent diffusion models do suggest that they represent some features of visual scenes’ 3D geometry. This is consistent with the hypothesis that they can in principle learn, at least to a limited degree, “world models” in a similar sense as Othello-GPT. Their latent space encodes structure-preserving, causally efficacious information that goes beyond the surface statistics of pixel space. This is an important clue to address speculations about Sora and the simulation hypothesis.
Back to Sora Link to heading
Like latent diffusion models used for image generation, Sora is trained end-to-end from visual inputs. Neither training nor generation is explicitly conditioned on physical variables. Yet, like latent diffusion models, its outputs exhibit striking regularities that call for an explanation. Having reviewed the different ways in which researchers discuss intuitive physics simulation and world models in cognitive science and machine learning, we are now better equipped to discuss the meaning and plausibility of the simulation hypothesis with respect to video generation.
The first thing we can say with some certainty, as I already hinted at earlier, is that Sora is fundamentally unlike composite models that make use of a dedicated “intuitive physics engine” to run simulations. In fact, in the literature on intuitive physics, deep learning models are commonly used as a foil for the IPE hypothesis. Sora has no built-in separation between perception, prediction and decision modules requiring an interface like a physics engine; just one high-dimensional space in which latent representations undergo successive transformations across layers.
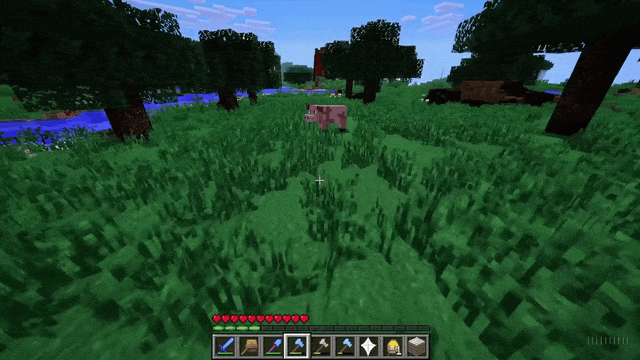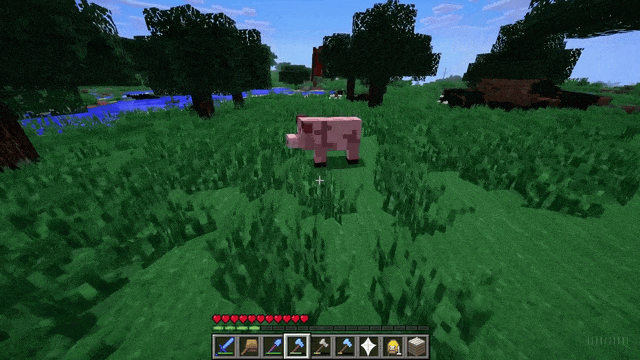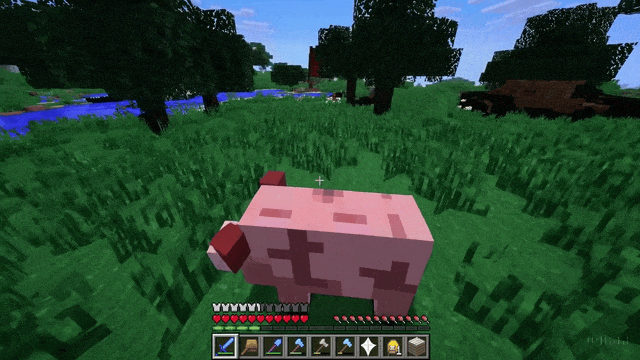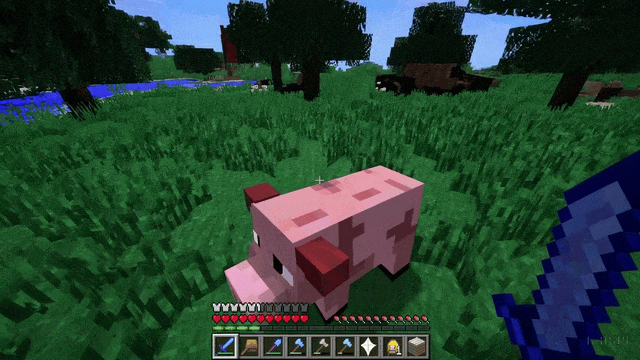
Sora is also quite different from the “world models” of Ha & Schmidhuber (2018). It doesn’t run simulations based on a history of discrete actions, observations, and reward signals. In that respect, OpenAI’s technical report is a bit misleading when it discusses examples of videos generated by prompting Sora with captions mentioning “Minecraft.” The generated videos certainly look like they were captured from a videogame like Minecraft: a first-person sandbox in which the controllable character moves and acts in a procedurally generated 3D world. But the technical report goes further in its interpretation of these outputs:
Sora can simultaneously control the player in Minecraft with a basic policy while also rendering the world and its dynamics in high fidelity.33
This suggests that Sora emulates a policy for an agent (the “controllable” character) as in offline RL. But there is no policy – or agent, actions, rewards – in the traditional sense here. Unlike Genie, Sora is not trained to induce latent actions from videos, and its outputs are not conditioned on such actions. There is interesting work showing one can learn policies by extracting action from generated video with an inverse dynamics model, but of course that also doesn’t apply to Sora without extra bells and whistles (besides, training a domain-general inverse dynamics model is an unsolved problem).34 If we take it at face value, the technical report implies that Sora has spontaneously learned to represent something like an implicit policy for the Minecraft character internally, but surely this is not something we can infer merely by looking at outputs. This is a rather bold claim that should be clarified and backed up by an analysis of what goes on inside the model.
So, Sora is unlike IPE models, unlike model-based RL world models, and (to a lesser extent) unlike Genie in important respects. Is it not a “world simulator” in the following strong sense:
- $Sim_1$: A system that runs forward-time simulations of an environment’s elements and dynamics, and whose predictions are conditioned on the outputs of such simulations.
Sora’s prediction of spacetime tokens is conditioned on the previous sequence of spacetime tokens; it doesn’t involve running a bunch of time-foward simulations about the 3D world depicted in the 2D video scene, then predicting next frames based on these simulations. Consider by analogy the case of Othello-GPT; it does not predict legal moves based on move sequences by running several internal simulations of future states of the game, like a traditional search algorithm, and conditioning its next-move prediction on the results.
However, we cannot rule out the hypothesis that Sora is a “world simulator” – or, somewhat less pompously, has a “world model” – in the weaker sense precisely inspired by systems like Othello-GPT:
- $Sim_2$: A system that learns structure-preserving, causally efficacious representations of properties of its input domain (including physical properties of 3D environments when inputs are visual scenes).
As we have seen, not only has it been shown that latent diffusion models encode information about the 3D geometry of visual scenes in their latent space, but we also have evidence that such information (at least with respect to variables like depth) is causally efficacious on behavior. As a DiT, Sora is fundamentally a latent diffusion model, albeit one with a Transformer backbone. It also differs from latent diffusion models like Stable Diffusion in two significant ways: it processes latent representations of videos (3D “spacetime” objects) instead of images, and it is likely to be much larger and trained on much more data. Consequently, one might expect findings about the representation of 3D geometry in Stable Diffusion to translate to a system like Sora; and one might also expect Sora to represent more “worldly properties” of its input domain, including, importantly, properties of processes that unfold through time.
This is where we enter purely speculative territory, because we simply lack interventional studies on video generation models, let alone models as capable as Sora. Nonetheless, if we were able to probe Sora through the tools of interpretability research, I wouldn’t be shocked to learn that one can in fact recover linearly decodable information about some aspects of intuitive physics – such as motion or object permanence – from its internal activations. I also wouldn’t be terribly surprised to learn that such information plays an active causal role in Sora’s predictions. This is consistent with what we know about much simpler diffusion models, and it is also consistent with the remarkable regularities observed in Sora’s outputs. Unfortunately, the relevant experimental evidence doesn’t (yet) exist, so all we are left with are informed guesses.
Critics like Gary Marcus have pointed to blatant violations of physics in some of Sora’s outputs as evidence against the simulation hypothesis.35 OpenAI’s own blog post and technical report on Sora acknowledge these limitations, and offer some examples of particularly egregious ones. In the videos excerpted below, for instance, one can see clear spatiotemporal inconsistencies, including violations of gravity, collision dynamics, solidity, and object permanence.


The first thing to note is that while such inconsistencies naturally jump out to us as uncanny, these videos also exhibit highly nontrivial consistencies. To be sure, strange things are happening; glasses levitate, liquids flow through glass, chairs morph into strange shapes, and people pop out of existence when occluded. But these anomalies stick out as strange partly because everything else looks pretty much as one would expect in a video. This is why these outputs look more like weird sci-fi special effects from a world with wonky physics than they look like abstract and chaotic visual patterns. The global 3D geometry of the scenes, for example, is fairly consistent; so are the motion trajectories of various scene elements.
The fact that Sora’s outputs clearly can get things wrong about intuitive physics – just as Stable Diffusion’s outputs can get things wrong about projective geometry – does not rule out the hypothesis that the model represents some aspects of 3D geometry and dynamics consistently. If there is anything there like “world model” in the weaker sense defined above, it is certainly not a perfect or complete one; it is likely to be patchy in various ways. Take Stable Diffusion’s latent representation of depth, for example; it clearly affects the generative process in highly nontrivial ways, even though it is merely approximative. The same could be true of Sora’s representations.
It is worth revisiting a point I made in passing when discussing Sora’s architecture. Like latent diffusion models used to generate images, Sora’s generative process does not occur in pixel space, but in latent space – the space in which latent representations of spacetime patches are encoded. This is presumably significant, because a number of commentators have suggested that Sora merely learns to interpolate common patterns in frame-by-frame pixel changes. One way to think about this suggestion is that Sora would merely approximate common transformations of the spatiotemporal “texture” of videos in pixel space. Thinking about how Sora generates videos in this way is potentially misleading. Everything that happens in Sora’s architecture between the encoder and decoder happens in latent space. As studies of latent diffusion models show, latent representations of properties such as depth can be causally efficacious from early diffusion timesteps even when the corresponding images in pixel space for the same timesteps contain no corresponding information. This could be true of Sora too: it is not implausible that latent representations of properties related to the intuitive physics of the scene are causally efficacious on the generative process early even at early diffusion timesteps.
Someone like Yann LeCun may disagree with this assessment because Sora’s training objective is about pixel-level reconstruction, even though the generative process occurs in latent space. And so, the argument goes, Sora’s latent representations of video scenes can’t be expected to be all that abstract. But the very same argument would apply to latent diffusion models used for image generation; and, again, we have concrete evidence that these models do learn useful abstract representations of features like depth. Perhaps V-JEPA’s representations are even more abstract and structured than Sora’s; but this is an open empirical question.
Concluding thoughts Link to heading
So, are video generation models like Sora world simulators? Maybe in a weak sense, but not necessarily in the way one might think. Their generative process is not conditioned on forward-time simulations of intuitive physics, as one could do with an intuitive physics engine; but it might be shaped by latent representations of key aspects of 3D geometry and dynamics. In that latter (and weaker) sense, it is rather plausible that Sora has a limited “world model”, in the same way as latent diffusion models used for image generation have a – more limited still – “world model”. But we don’t know for sure, not until some research group probes Sora in the right way. OpenAI still occasionally delves into interpretability research, so there is hope; although I would be happy to see interpretability efforts from the broader research community with open weights video generation models like Stable Video. While far less capable than Sora, these models have the merit of being research friendly.
While we are engaging in conjecture, let me add a quick speculative note about what the future may hold for video generation models. I argued that Sora is not a simulator in the specific sense that it does not predict video frames by running a series of simulations of the scene first. But perhaps Sora – or some more capable video generation model – could be used as a simulator within a more composite system. For example, the authors of the Genie paper hint at the idea that a similar model could be used to generate a diverse set of simulated environments for training RL agents, as in the “World Models” paper. Looking ahead, we can imagine future robotic systems using three main components:
- A large vision-language model to parse linguistic instructions, translate into plans, and reason about visual inputs;
- A large video generation model to “simulate” possible future observations for low-level planning;
- A general inverse dynamics model to extract suitable actions from these simulations and execute the plan accordingly.
Perhaps (2) and (3) could be merged within a general Genie-style generative model with a built-in (or perhaps learned) ability to represent latent actions; or perhaps all three models could be merged into a giant Gato-style multimodal model that can parse and generate linguistic, spatiotemporal, and action tokens.36 These speculative scenarios do suggest a path from generative modeling of videos to “world simulation” in the stronger sense.
Let me conclude with an intriguing open question. Whatever place video generation models may have in the future of AI and robotics, one might wonder – as with any deep learning model – whether they will become relevant to cognitive science in non-superficial ways. As discussed, there is still no consensus regarding the extent to which human physical reasoning does rely on explicit simulations with an intuitive physics engine. Perhaps the progress of video generation models, and future research on their viability as actual simulators within an agent-based architecture, will put some pressure on the IPE model. It may also lead to interesting discussions about whether a neural network that can reliably simulate intuitive physics should be taken to implement the core mechanisms of an IPE learned end-to-end, as opposed to being a genuine alternative to the IPE model of intuitive physics. This discussion would probably inspire new debates about the innateness of intuitive physics, although it is doubtful that video generation models trained on internet-scale data would constitute plausible model learners (any more than large language models trained on gigantic corpora offer plausible models of language acquisition). This is why it could be interesting to eventually train such models on developmentally realistic and ecologically valid data from head-mounted cameras worn by infants – like the SAYCam dataset.37 Whatever one might think about Sora and OpenAI, it’s exciting to ponder how video generation models might become relevant to key research questions in deep learning and cognitive science beyond their mere entertainment value. We’ll see what it takes to go from GIF generators to world simulators.
If you would like to cite this post in an academic context, you can use the following BibTeX snippet:
-
Depending on who you ask, before Sora the best text-to-video models would be Google’s Lumiere, Runway’s Gen-2, Morph Studio, Pika, or StabilityAI’s Stable Video. Released samples from Sora blow them out of the water – see for yourself. ↩︎
-
The technical report on Sora is titled “Video generation models as world simulators”. ↩︎
-
This is the first sentence from the Sora blog post. ↩︎
-
Brooks, T., Peebles, B., et al. (2024). Video generation models as world simulators. https://openai.com/research/video-generation-models-as-world-simulators ↩︎
-
Runway Research Blog, Introducing General World Models. ↩︎
-
Tian, Y., Ren, J., Chai, M., Olszewski, K., Peng, X., Metaxas, D. N., & Tulyakov, S. (2021). A Good Image Generator Is What You Need for High-Resolution Video Synthesis. International Conference on Learning Representations. https://openreview.net/forum?id=6puCSjH3hwA ↩︎
-
See Saining Xie’s Twitter thread. ↩︎
-
Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 4195–4205. ↩︎
-
Chen, S., Xu, M., Ren, J., Cong, Y., He, S., Xie, Y., Sinha, A., Luo, P., Xiang, T., & Perez-Rua, J.-M. (2023). GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation (arXiv:2312.04557; Version 1). arXiv. https://doi.org/10.48550/arXiv.2312.04557 ↩︎
-
Not to be confused with the other simulation hypothesis popularized by Nick Bostrom, according to which we live in a simulation. OpenAI’s simulation hypothesis is that Sora can simulate – in some sense to be elucidated – the physical world. ↩︎
-
Liu, R., Wei, J., Gu, S. S., Wu, T.-Y., Vosoughi, S., Cui, C., Zhou, D., & Dai, A. M. (2023). Mind’s Eye: Grounded Language Model Reasoning through Simulation. The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=4rXMRuoJlai ↩︎
-
Wong, L., Grand, G., Lew, A. K., Goodman, N. D., Mansinghka, V. K., Andreas, J., & Tenenbaum, J. B. (2023). From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought (arXiv:2306.12672). arXiv. https://doi.org/10.48550/arXiv.2306.12672 ↩︎
-
The interpretation of infant reactions in the violation-of-expectations paradigm has been debated, but this debate lies beyond the scope of my blog post. For an overview, see Margoni, F., Surian, L., & Baillargeon, R. (2023). The violation-of-expectation paradigm: A conceptual overview. Psychological Review. https://doi.org/10.1037/rev0000450 ↩︎
-
There’s pretty strong evidence that at least some aspects of intuitive physics are innate in some species, if not in humans. For example, a recent paper found that newborn chicks raised in a controlled environment where objects never occlude each other or teleport from one location to another still behave as if object permanence were true. ↩︎
-
Battaglia, P. W., Hamrick, J. B., & Tenenbaum, J. B. (2013). Simulation as an engine of physical scene understanding. Proceedings of the National Academy of Sciences, 110(45), 18327–18332. https://doi.org/10.1073/pnas.1306572110 ↩︎
-
Ullman, T. D., Spelke, E., Battaglia, P., & Tenenbaum, J. B. (2017). Mind Games: Game Engines as an Architecture for Intuitive Physics. Trends in Cognitive Sciences, 21(9), 649–665. https://doi.org/10.1016/j.tics.2017.05.012 ↩︎
-
Interested readers may refer to this useful review, although it is now slightly dated: Kubricht, J. R., Holyoak, K. J., & Lu, H. (2017). Intuitive Physics: Current Research and Controversies. Trends in Cognitive Sciences, 21(10), 749–759. https://doi.org/10.1016/j.tics.2017.06.002 ↩︎
-
Liu, Y., Ayzenberg, V., & Lourenco, S. F. (2024). Object geometry serves humans’ intuitive physics of stability. Scientific Reports, 14(1), Article 1. https://doi.org/10.1038/s41598-024-51677-5 ↩︎
-
Ha, D., & Schmidhuber, J. (2018). World Models. https://doi.org/10.5281/zenodo.1207631 ↩︎
-
Deitke, M., Batra, D., Bisk, Y., Campari, T., Chang, A. X., Chaplot, D. S., Chen, C., D’Arpino, C. P., Ehsani, K., Farhadi, A., Fei-Fei, L., Francis, A., Gan, C., Grauman, K., Hall, D., Han, W., Jain, U., Kembhavi, A., Krantz, J., … Wu, J. (2022). Retrospectives on the Embodied AI Workshop (arXiv:2210.06849). arXiv. https://doi.org/10.48550/arXiv.2210.06849 ↩︎
-
Bruce, J., Dennis, M., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., Aytar, Y., Bechtle, S., Behbahani, F., Chan, S., Heess, N., Gonzalez, L., Osindero, S., Ozair, S., Reed, S., … Rocktäschel, T. (2024). Genie: Generative Interactive Environments (arXiv:2402.15391). arXiv. http://arxiv.org/abs/2402.15391 ↩︎
-
LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. https://openreview.net/forum?id=BZ5a1r-kVsf ↩︎
-
Yildirim, I., & Paul, L. A. (2023). From task structures to world models: What do LLMs know? Trends in Cognitive Sciences. ↩︎
-
Cameron Buckner and I provide an overview of these discussions here: Millière, R., & Buckner, C. (2024). A Philosophical Introduction to Language Models – Part I: Continuity With Classic Debates. https://doi.org/10.48550/arXiv.2401.03910 ↩︎
-
Li, K., Hopkins, A. K., Bau, D., Viégas, F., Pfister, H., & Wattenberg, M. (2023). Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. https://doi.org/10.48550/arXiv.2210.13382 ↩︎
-
Jacqueline Harding provides an excellent discussion of these criteria in this paper: Harding, J. (2023). Operationalising Representation in Natural Language Processing. https://doi.org/10.48550/arXiv.2306.08193 ↩︎
-
Nanda, N., Lee, A., & Wattenberg, M. (2023). Emergent Linear Representations in World Models of Self-Supervised Sequence Models. https://doi.org/10.48550/arXiv.2309.00941 ↩︎
-
Kıcıman, E., Ness, R., Sharma, A., & Tan, C. (2023). Causal Reasoning and Large Language Models: Opening a New Frontier for Causality (arXiv:2305.00050). arXiv. https://doi.org/10.48550/arXiv.2305.00050 ↩︎
-
Brooks, T., Peebles, B., et al. (2024). Video generation models as world simulators. https://openai.com/research/video-generation-models-as-world-simulators ↩︎
-
Du, Y., Yang, M., Dai, B., Dai, H., Nachum, O., Tenenbaum, J. B., Schuurmans, D., & Abbeel, P. (2023). Learning Universal Policies via Text-Guided Video Generation. https://doi.org/10.48550/arXiv.2302.00111 ↩︎
-
Marcus, G. (2024). Sora’s Surreal Physics [Substack newsletter]. Marcus on AI. https://garymarcus.substack.com/p/soras-surreal-physics ↩︎
-
Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S. G., Novikov, A., Barth-maron, G., Giménez, M., Sulsky, Y., Kay, J., Springenberg, J. T., Eccles, T., Bruce, J., Razavi, A., Edwards, A., Heess, N., Chen, Y., Hadsell, R., Vinyals, O., Bordbar, M., & Freitas, N. de. (2022). A Generalist Agent. Transactions on Machine Learning Research. https://openreview.net/forum?id=1ikK0kHjvj ↩︎
-
Vong, W. K., Wang, W., Orhan, A. E., & Lake, B. M. (2024). Grounded language acquisition through the eyes and ears of a single child. Science, 383(6682), 504–511. https://doi.org/10.1126/science.adi1374 ↩︎